
study
cs231n 2강 Image classfication pipeline 본문
Image Classification이란
: 사진을 컴퓨터에게 입력했을 때 사진에 나오는 객체(사람, 사물, 장소 등)를 판별하는 것을 말한다.

컴퓨터에게 이미지는 숫자들의 집합에 불과하며 그 숫자들의 집합을 array(배열)라고 부른다
각 픽셀의 밝기 값은 0~255 범위의 정수로 표현
이미지는 3차원 배열로 width, height, channel로 구성되며 channel의 경우 RGB(Red, Green, Blue) 또는 흑백을 말한다

기존의 이미지 분류에서는 이미지 특징점(edge, shape)을 통해 이미지 분류를 시도하였다
하지만 이러한 방법은 확장성이 없다
왜냐하면 위의 인물사진에서 작은 변형만 일어나더라도 분류 정확도가 떨어지기 때문이다
그래서 데이터 중심의 접근 방법(Data-driven approach)이 필요하다

사진을 특징을 하나하나 규정하기보다는 image와 label(객체의 이름)이 달린 데이터를 수집
1) train 함수 : 학습시킬 image와 label을 통해 model을 만들어 낸다
2) predict 함수 : 학습된 model을 통해 학습하지 않은 image의 label를 예측한다
Nearest Neighbor Classifier(최근접 이웃 분류기)
: 이 분류기는 컨볼루션 신경망 방법과는 관련이 없으며, 실제 문제를 풀 때 자주 사용되지는 않지만, 이미지 분류 문제에 대한 기본적인 접근 방법을 알 수 있도록 한다. 최근접 이웃 분류기는 테스트 이미지를 취해 학습된 이미지에서 가장 유사한 이미지를 결과로 출력해준다. 아래 사진의 경우 비행기라는 test image를 입력했을 때 train 이미지에서 가장 유사한 이미지가 출력된 것을 확인할 수 있다

그렇다면 이미지 쌍이 있을 때, 어떻게 비교를 할 것인지가 중요하다
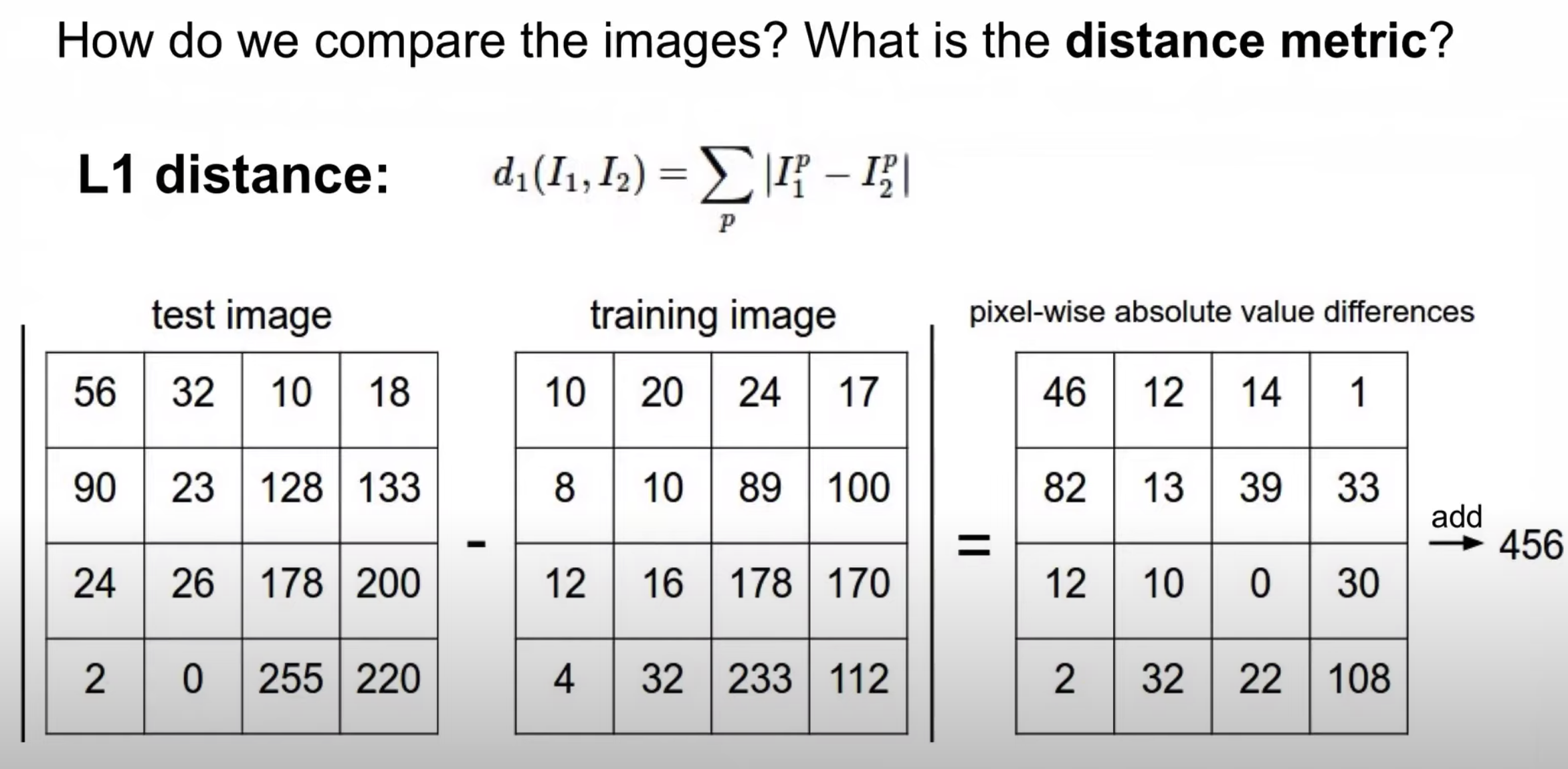
맨하탄 거리라고 불리는 L1 distance는 test image와 train image의 픽셀 값들을 뺀 결과를 더해주는 것을 의미한다
위의 식에서 P는 pixel의 개수를 의미하며, 10(width)x10(height)x3(channel)의 경우 p는 300이 된다
I는 입력된 이미지로 test image, train image를 의미한다
절대값을 사용하는 이유로는 거리가 음수로 표현될 수 없기 때문이다
그러므로 각 픽셀에 대한 | l(1) - l(2) |는 300개를 다 더한 값이 유사도가 된다
k - Nearest Neighbor (kNN) 분류기
학습 데이터셋에서 가장 가까운 하나의 이미지만을 찾는 것이 아니라, 가장 가까운 k 개의 이미지를 찾아서 테스트 이미지의 라벨에 대해 투표하도록 하는 것이다. 여기서 k = 1 인 경우, 원래의 Nearest Neighbor 분류기가 된다. 5-NN에서 흰색 부분은 투표를 가장 많이 받은 label이 여러개 있는 것을 나타낸다. K-NN의 경우 다수결로 투표하기 때문에 k의 갯수는 홀수로 지정 해야한다. 직관적으로 k 값이 커질수록 분류기는 이상점(outlier)에 더 강인하고, 분류 경계가 부드러워지는 효과가 있다.

k개의 개수에 따라서 분류 정확도가 다르기 때문에 최적의 k개의 개수를 찾는 것이 중요하다
Cross validation(k fold 교차검증)
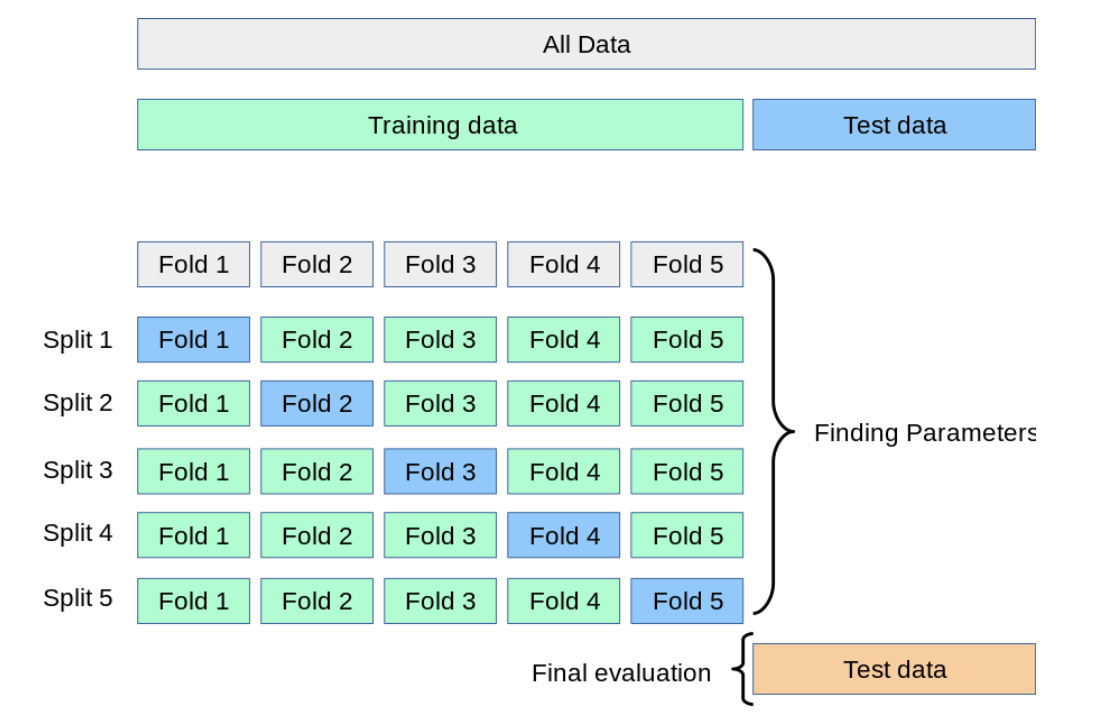
training data를 k개로 나누며, 위의 경우 k는 5로 데이터를 5등분으로 나눠 4개를 training data로 사용하고 남은 1개 dataset을 validation data로 사용하며 최종적으로 test data를 통해 정확도를 산출한다. Cross validation의 경우 모든 데이터 셋을 사용하여 평가 결과를 조금 더 일반화할 수 있으며 데이터가 부족할 경우 과소적합의 문제를 어느정도 해결할 수 있는 방법이다. 하지만 lteration 횟수가 많아질수록 모델 훈련/평가 시간이 오래 걸리는 단점이 있다
Linear Classification

선형 분류의 경우 parameter 접근 방식으로 x는 주어지는 이미지, W는 parameter, b는 bias를 의미한다. image의 class가 10개라고 가정한다면 이미지를 평평하게 핀다면 x는 32*32*3으로 3072*1의 행렬을 가지며 f는 10개의 클래스 가져 10*1의 행렬을 가진다. 이 수식을 만족하기 위해서 W는 10*3072의 행렬을 가져야 한다.(아래 사진 참고)

행렬 연산의 구체적인 예시

label = 3개, image pixel = 4개라고 가정한다면
W * X(4*1) + b = (3*1)이 만족하기 위해서는 W = 3*4의 행렬을 가져야 한다
구체적으로 계산하자면
(0.2 * 56 -0.5 * 231 + 0.1 * 24 + 2.0 * 2) + 1.1 = -96.8이 나오며 이 score는 cat의 score를 의미한다
'CS231n' 카테고리의 다른 글
| CS231 6강 training neural networks 1 (0) | 2020.12.03 |
|---|---|
| CS231n 5강 Convolutional Neural Networks (0) | 2020.12.02 |
| CS231n 4강 Backpropagation and neural networks (0) | 2020.10.31 |
| CS231n 3강 Loss Functions and Optimization (0) | 2020.10.24 |
| CS231n 1강 introduction to CNN (0) | 2020.10.09 |



