
study
CS231n 5강 Convolutional Neural Networks 본문
안녕하세요
5강 이전에 강의 내용들은 Neural Network와 관련되어 있었습니다
CNN은 Neural Network에서 Convolution Layer가 추가된 딥러닝 알고리즘입니다
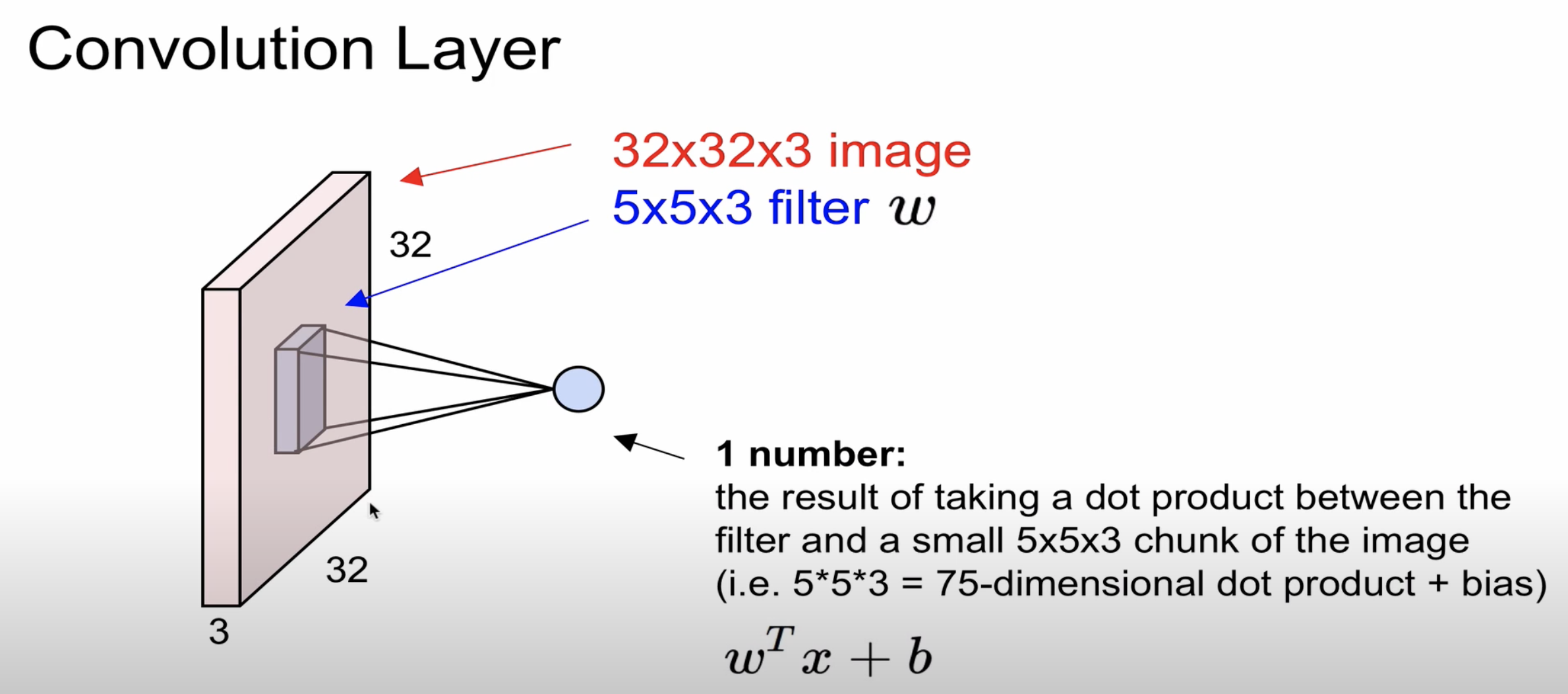
이미지의 경우 width, height, depth로 구성되어 있으며 filter를 통해 이미지에서 특징점을 뽑는 것을
Convolution Layer라고 부릅니다
image의 depth와 filter의 depth는 동일해야 합니다
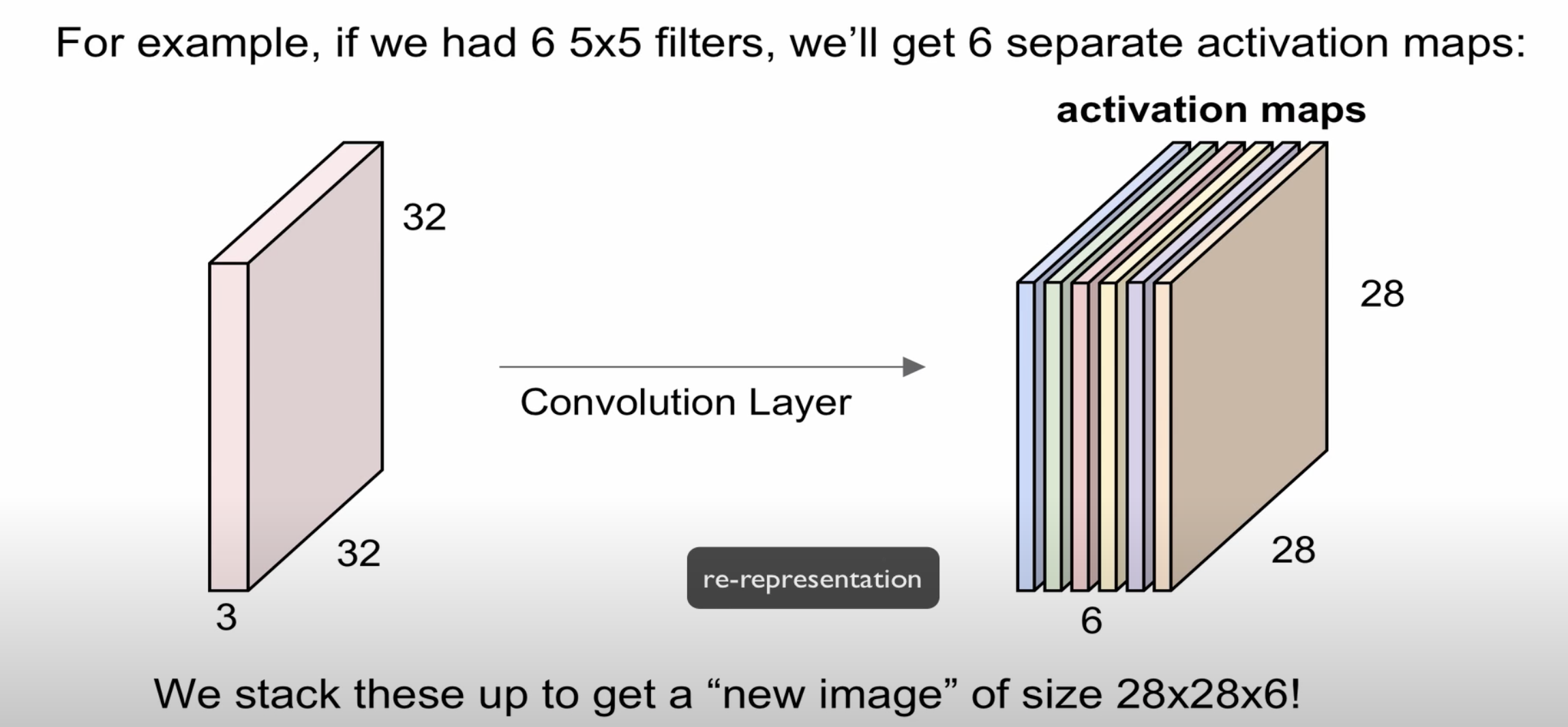
image에서 filter 연산을 통해 생성된 것을 activation map이라고 부릅니다
하나의 filter는 하나의 activation map을 만듭니다

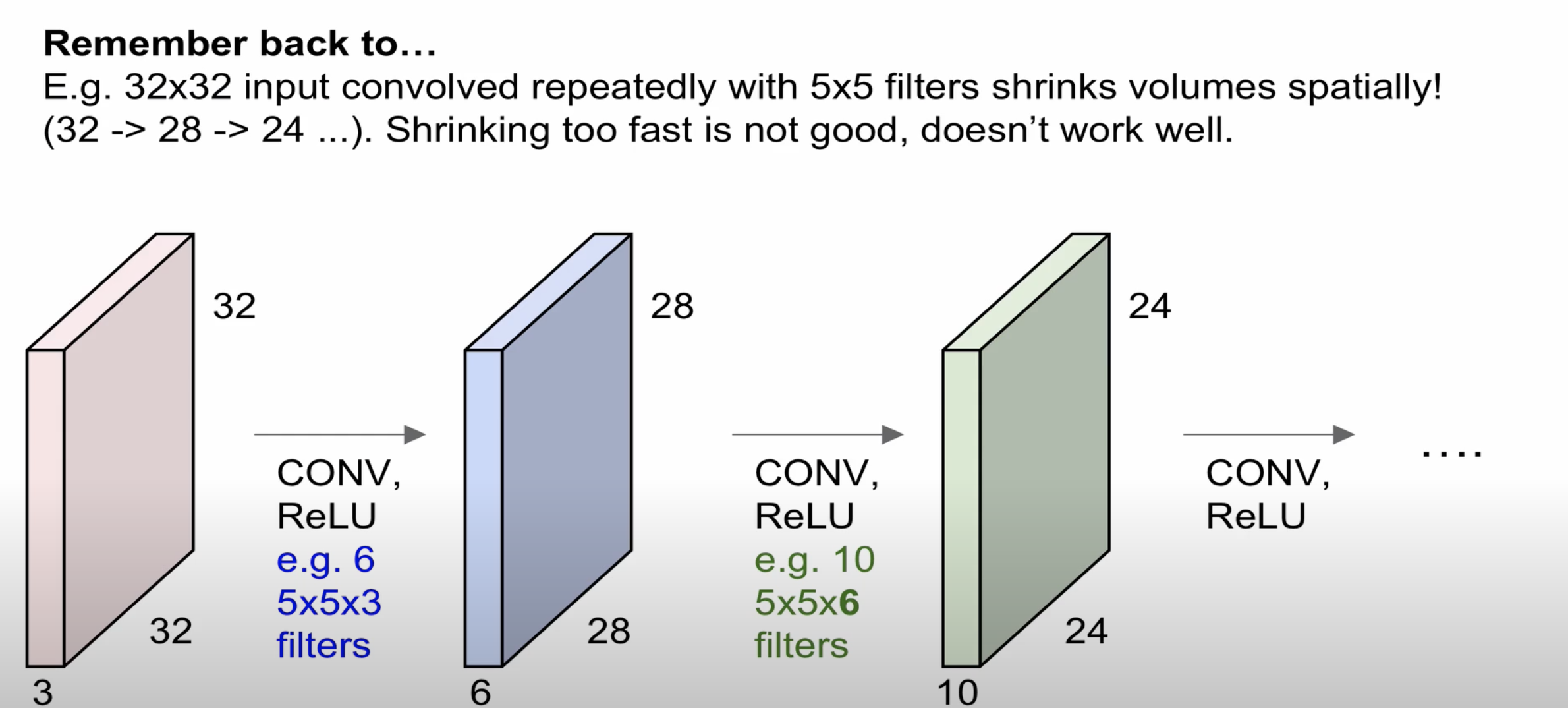
32 * 32 * 3(width, height, depth) 이미지에서 5 * 5 * 3의 filter(6개)를 연산하면 28 * 28 * 6의 형태로 변환된다
그리고 다시 Convolution과 Relu 과정을 통해 5 * 5 * 6의 filter(10개)를 연산하면
24 * 24 * 10의 형태로 변환된 것을 알 수 있으며 이런 과정들이 기본적인 CNN의 구조입니다

Low-Level Feature는 원본 이미지에서 Convolution Layer를 한 번 통과해서 얻은 feature를 시각화 한 부분입니다
Mid-Level Feature는 Low-Level에서 뽑은 특징점을 다시 Convolution Layer를 통과시켜 나온 feature를 시각화했습니다
High-Level Feature는 Mid-Level Feature에서 구한 feature를 다시 Convolution Layer를 통과시킨 후 나온 특징입니다
Convolution Layer를 여러 번 통과하면서 이미지의 특징점들이 선명하게 나타나는 것을 확인할 수 있습니다

filter의 역할에 대해 구체적으로 설명하겠습니다
해당 자료에서 보시면 32개의 filter로 구성되어 있습니다
파란색으로 연결된 부분을 보시면 주황색 filter를 통해 왼쪽 상단에 있는 이미지에서 주황색 부분이
흰색으로 표시되며, 아닌 부분은 검은색으로 표시된 것을 확인할 수 있습니다
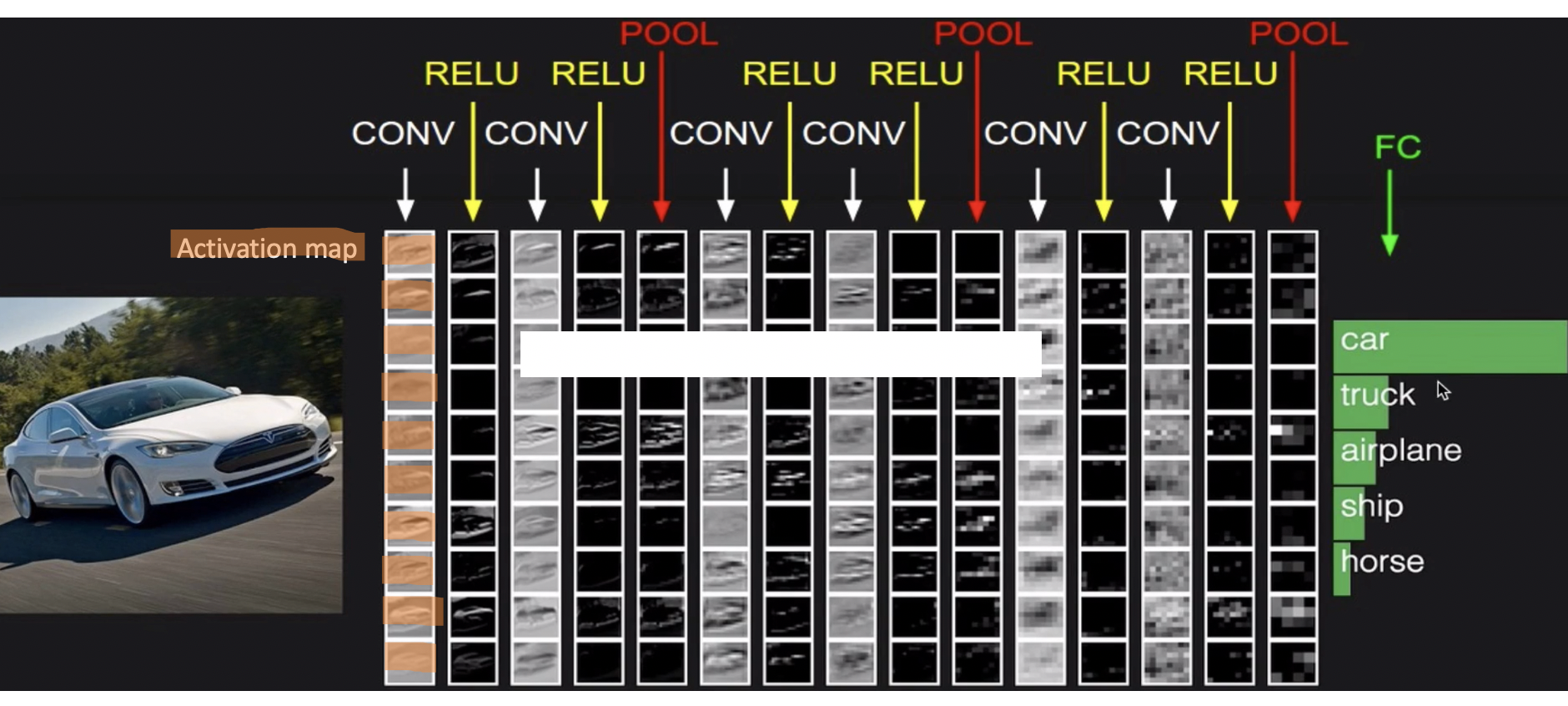
CNN의 전체 과정을 요약하자면 위와 같습니다
Convolution, Relu, Pooling이 반복되며 마지막에 FC(fully connected, 분류를 위한 Layer)로 이루어진 구조입니다
CONV에서 column은 이미지의 수가 되며 row는 activation map을 의미합니다
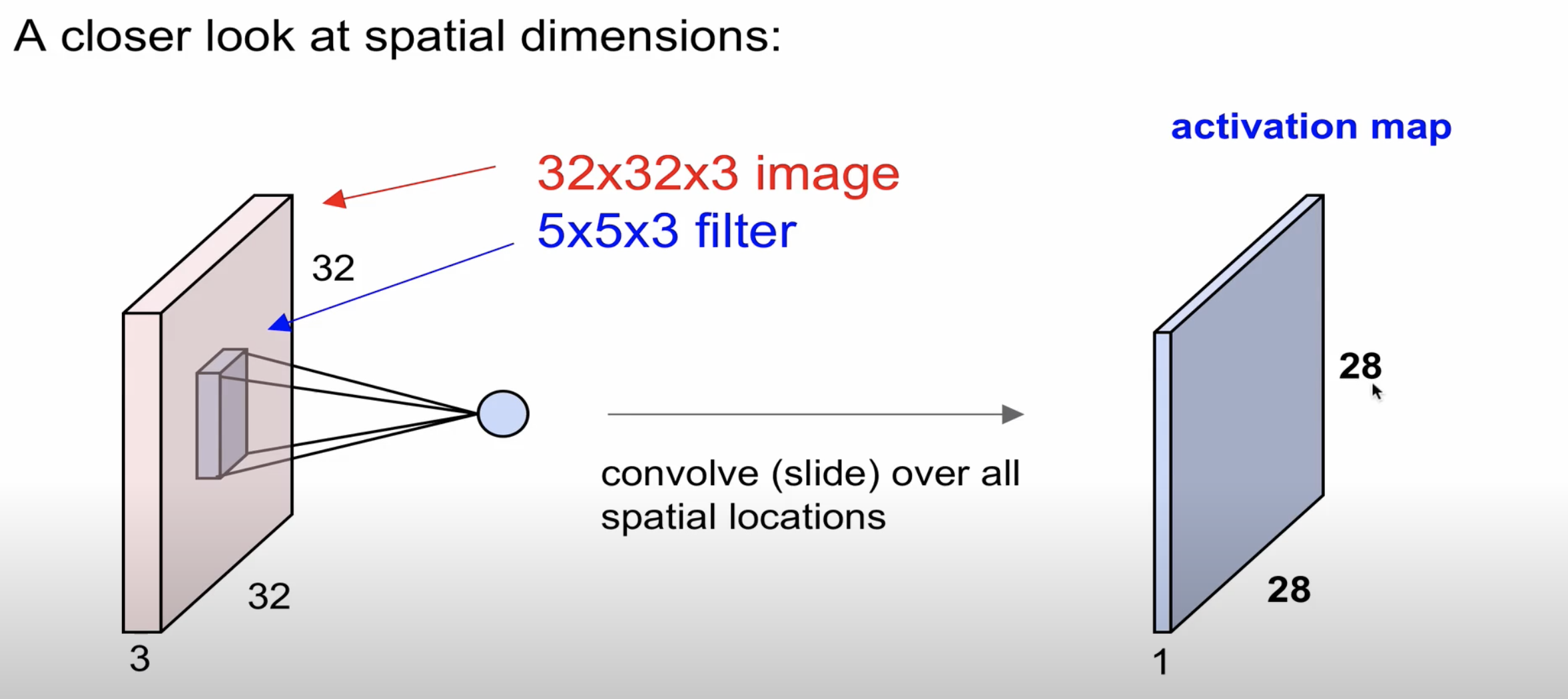
32 * 32 * 3의 이미지에서 filter(1개)을 통해 28 * 28 * 1의 activation map이 나온다
여기서 28이라는 것은 어떻게 구할 수 있을까요??

7 * 7의 이미지에 대해 3 *3 filter 연산을 하게 되면 위와 같이 진행된다
그래서 최종적으로 output의 크기는 5 * 5로 표현이 된다
위의 자료에서 보시면 옆으로 이동하는 크기가 1인 것을 알 수 있습니다
이동하는 크기를 stride라고 부릅니다
stride를 2로 주면 output의 크기가 어떻게 될까요?

위와 같이 output의 크기는 3 * 3이 됩니다

output의 크기를 쉽게 구하는 방법이 있습니다
N = 이미지의 width, height , F = filter의 width, height입니다
stride가 3인 경우에는 정수로 떨어지지 않기 때문에 원칙적으로는 사용하지 않습니다

7 * 7의 이미지가 3 * 3 filter을 통해 연산을 하면 5 * 5의 output의 크기를 가집니다
원래 이미지의 크기가 줄어든 것을 알 수 있습니다 그래서 원래 이미지 크기를 보존하기 위해 제로 패딩을 사용합니다
제로 패딩이란 원본 이미지의 가장자리를 0으로 채워 filter 연산을 하더라도 output의 크기가 동일합니다
제로 패딩의 다른 장점으로는 CNN에서 이미지의 외각을 인식하는 효과도 있습니다

F는 필터의 크기로 padding의 크기는 (F-1) /2로 쉽게 구할 수 있습니다
padding을 사용하지 않으면 output의 크기가 줄어듭니다
32 * 32의 이미지의 경우 8번 정도 Convolution Layer를 통과할 수 있습니다
위에서 보셨다시피 Convolution Layer를 통과할수록 이미지의 feature가 잘 뽑히는 것을 알 수 있습니다
그렇기 때문에 zero padding을 통해 여러 번의 Convolution Layer를 통과시킬 수 있습니다

간단한 문제를 내보겠습니다
5 * 5 filter(10개)의 파라미터 수는 몇 개일까요?
filter의 depth는 image의 depth와 동일하기 때문에 3으로 5 * 5 * 3으로 75가 나옵니다 여기서 bias에 해당하는 1을 더하며
filter의 수만큼 곱해주면 최종적으로 76 * 10으로 760개의 파라미터를 가지는 것을 알 수 있습니다
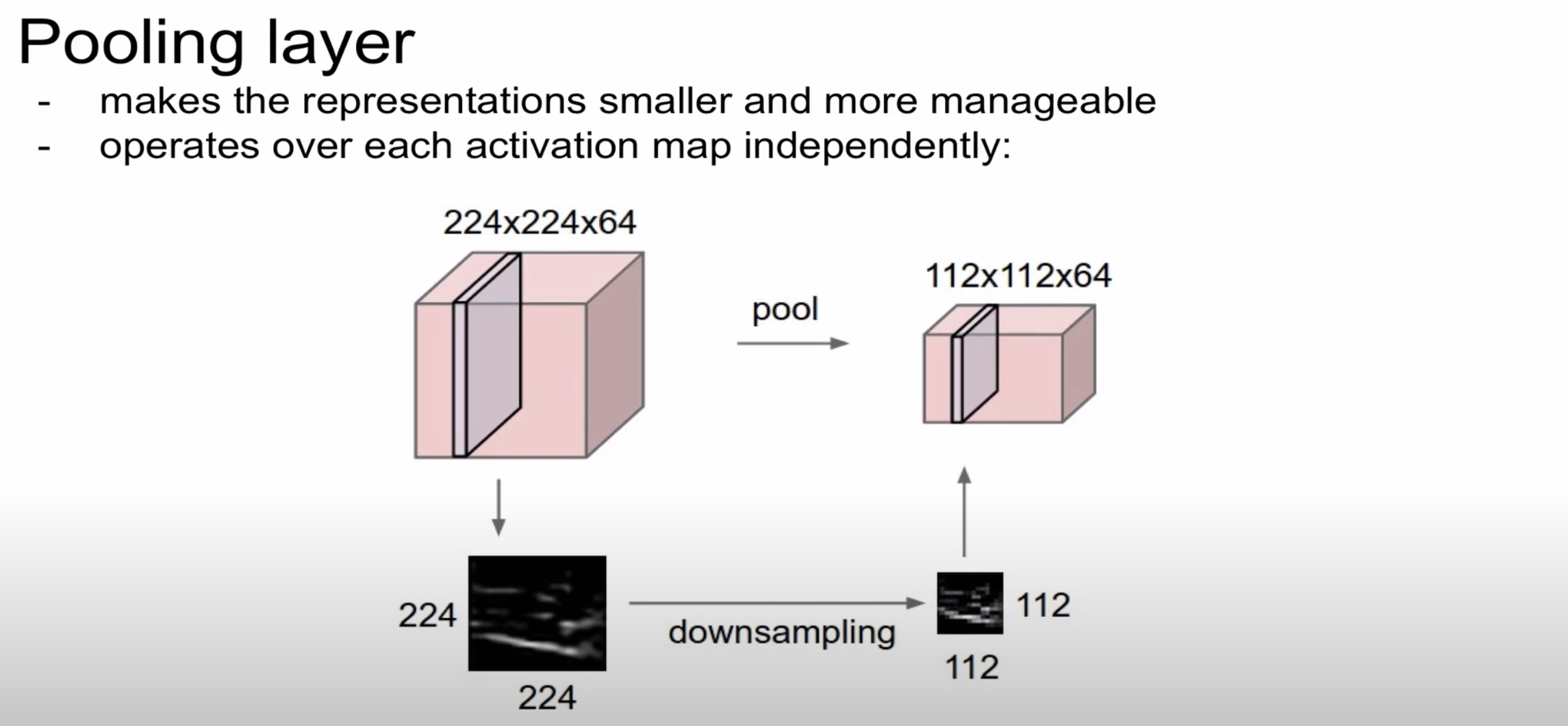
이번에 살펴볼 개념은 바로 Pooling Layer입니다
풀링 레이어는 컨볼류션 레이어의 출력 데이터를 입력으로 받아서 출력 데이터(Activation Map)의 크기를 줄이거나 특정
데이터를 강조하는 용도로 사용됩니다
Pooling layer에는 파라미터와 padding이 없습니다
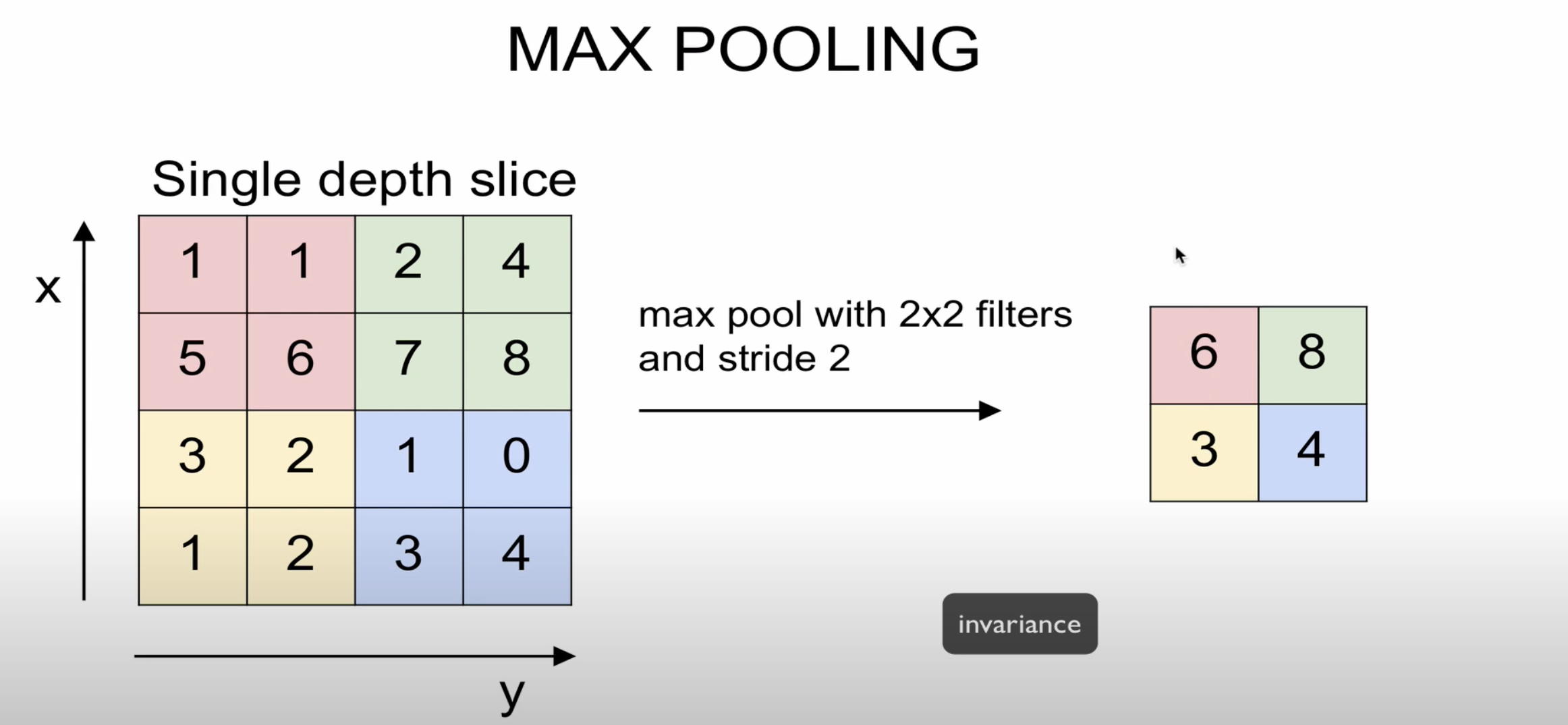
일반적으로 max Pooling을 많이 사용합니다
stride가 2라고 가정할 때 2 * 2 크기에서 가장 큰 값을 출력하는 형식입니다
Pooling을 통해 OutPut의 크기를 줄일 수 있습니다
물론 정보 손실이 되지 않느냐에 대한 의문이 있을 수 있지만 Pooling을 통해 역설적이게도
불변성을 얻을 수 있다고 합니다
CNN 구조의 마지막 단계인 FC(fully connected layer)에 대해 설명하겠습니다
fully connected layer
: "완전 연결되었다"는 뜻은 한 층(layer)의 모든 뉴런이 그다음 층(layer)의 모든 뉴런과 연결된 상태를 말합니다. 1차원 배열의 형태로 평탄화된 행렬을 통해 이미지를 분류하는데 사용되는 계층입니다. Fully connected layer를 Dense layer라고도 부릅니다. 쉽게 설명드리면 1차원 형태로 변환하여 softmax를 통해 해당 이미지가 어느 객체에 속하는지 분류하는 layer입니다.
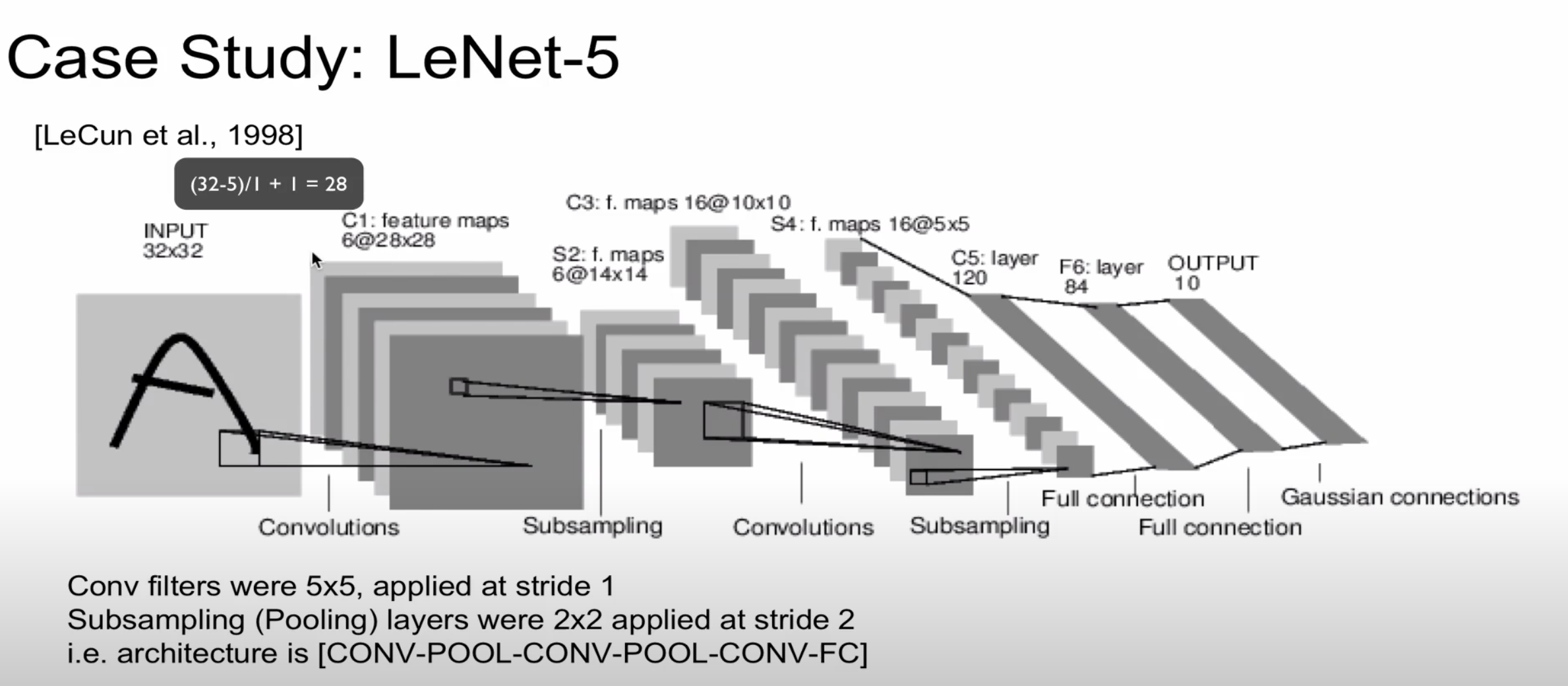
해당 자료는 LeNet-5로 현재는 많이 사용하지 않는 알고리즘입니다
하지만 구조가 단순하여 앞에서 배웠던 내용을 복습해보겠습니다
32 * 32 이미지에서 5 * 5 filter 연산을 하게 되면 28 * 28의 크기가 나옵니다
subsampling(pooling) 과정에서는 2 * 2 filter와 stride가 2입니다
(28-2) / 2 + 1 = 14가 나오기 때문에 S2에서는 14 * 14가 나오는 것을 알 수 있습니다

AlexNet의 구조입니다 일반적인 CNN 구조라는 것을 한눈에 알 수 있습니다
AlexNet의 경우 Normalization이 있는데 효과가 별로 없어 이후에 나오는 Net에는 사라졌습니다
또한 layer를 통과할수록 size는 작아지지만 filter의 수는 늘어나는 것을 알 수 있습니다
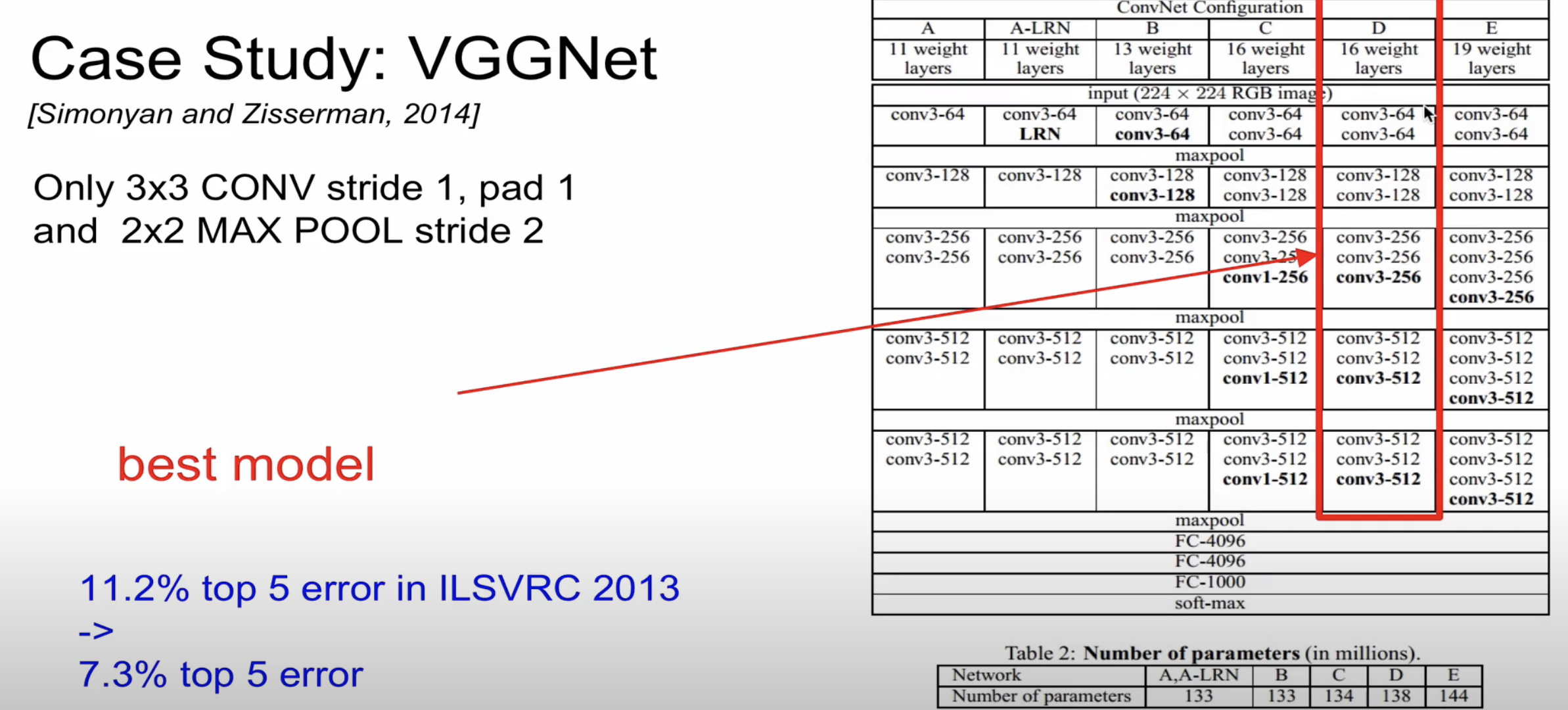
다음은 VGGNet의 구조입니다
VGGNet의 경우 convolution layer에서 filter 3 * 3, stride 1, padding 1을 전체 layer에게 동일하게 주었으며
pooling의 경우에도 filter 2 * 2, stride 2로 동일하게 전체 layer에게 주었습니다

구체적으로 VGGNet을 살펴보겠습니다
VGGNet도 이미지의 크기는 줄어들지만 filter의 크기는 증가하는 것을 알 수 있습니다
Total memory의 경우 32bit(4Byte)로 표현되어 * 4를 해주었으며 한 장의 이미지를 처리하는데 93MB가
필요하다는 것을 의미하며 역전파를 고려하면 126MB가 필요함을 시사합니다
그리고 중요한 점은 fully connected layer에서 많은 파라미터가 존재하여 계산하는데 오랜 시간이 소요됩니다
이를 해결하기 위해 이후에 나오는 Net은 FC layer를 없애고 average pooling을 사용하였습니다
average pooling을 사용하게 되면 7 * 7 * 512에서 7 * 7(단일 column으로 변환)이 없어지기 때문에 연산량을 줄일 수 있으면서도 정확도적인 부분도 차이가 없습니다

GoogleNet(InceptionNet)의 구조입니다
2014년도의 이미지 분류 경진대회에서 1등을 한 알고리즘이지만 구조가 복잡한 것을 알 수 있습니다
그래서 2등을 한 VGGNet을 대중적으로 사용하는 경향이 있습니다

중요한 점은 바로 average pooling 계층입니다
FC layer가 빠지고 avg pool을 통해 1차원 단일 column으로 변환한 것을 알 수 있습니다(1*1*1024)
그래서 파라미터 수가 VGGNet보다 적은 것을 확인할 수 있습니다(138M->5M)
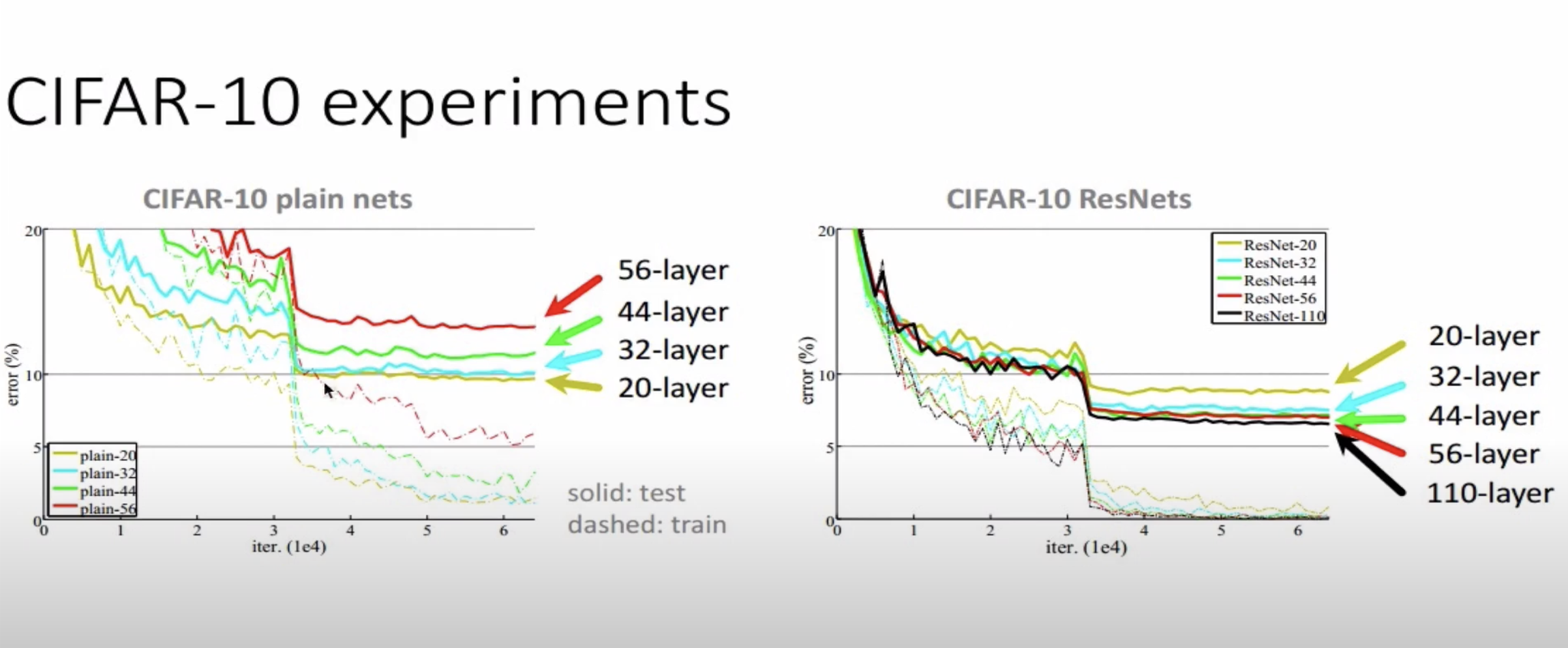
왼쪽 그림을 보면 기존 Net의 경우 layer가 깊어질수록 error가 커지는 것을 알 수 있습니다
오른쪽 그림(ResNet)을 보면 layer가 깊어질수록 errorr가 줄어드는 것을 확인할 수 있습니다

보시면 Batch Normalization이 추가된 것을 알 수 있습니다
그리고 AlexNet의 경우 learing rate를 0,01로 설정하였는데 ResNet의 경우 Batch Normalization 때문에 0.1로 설정하였습니다 또한 Batch Normalization을 하는 경우 dropout을 사용하지 않는다고 말합니다
'CS231n' 카테고리의 다른 글
| CS231 7장 training neural networks 2 (0) | 2020.12.05 |
|---|---|
| CS231 6강 training neural networks 1 (0) | 2020.12.03 |
| CS231n 4강 Backpropagation and neural networks (0) | 2020.10.31 |
| CS231n 3강 Loss Functions and Optimization (0) | 2020.10.24 |
| cs231n 2강 Image classfication pipeline (0) | 2020.10.09 |



